What did You learn today ?
What was the most important thing You learned this year ?
No direct guidance :: Learner L must identify patterns or relationships from raw input on her own.
Pattern discovery :: Observation often involves recognizing and understanding patterns in the environment, which mirrors what happens in unsupervised learning.
Learning from the environment :: L derives insights from the world or data without external labels or supervision.
What is Your most favorite game / way of playing ?
Any game You would like to bring & play with Your colleagues during the Congress ?
Classical Conditioning: Involves pairing a neutral stimulus with a meaningful one to elicit a similar response (e.g., Pavlov’s dogs salivating at the sound of a bell).
Operant Conditioning: Involves learning through rewards or punishments, where behaviors are strengthened or weakened based on their consequences (e.g., Thorndike’s Law of Effect).
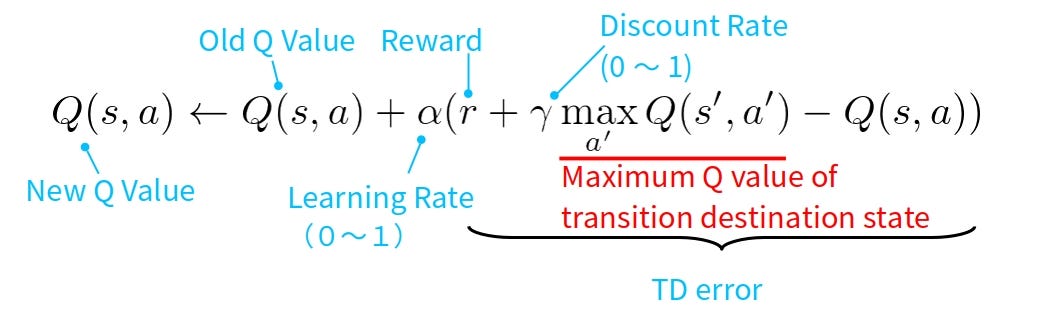
Q-learning is a model-free reinforcement learning algorithm that enables an agent to learn an optimal policy for decision-making. It works by estimating the Q-values (action-value function), which represent the expected cumulative reward for taking an action in a given state and following the best future actions. The agent updates Q-values iteratively using the formula: