

Left-hand and right-hand version 1 prototypes of Personal Primer (PP) artifact with integrated speech capabilities, e-ink displays and touchless gesture command & control interface.

Anyone can build his own Personal Primer from publicly available off-the-shelf components.
.png)
Homepage of https://fibel.digital

Microsoft's Schlaumaeuse is a well-known DRAA among German pre-schoolers.

Google's Read Along app belong to most well-known DRAAs.
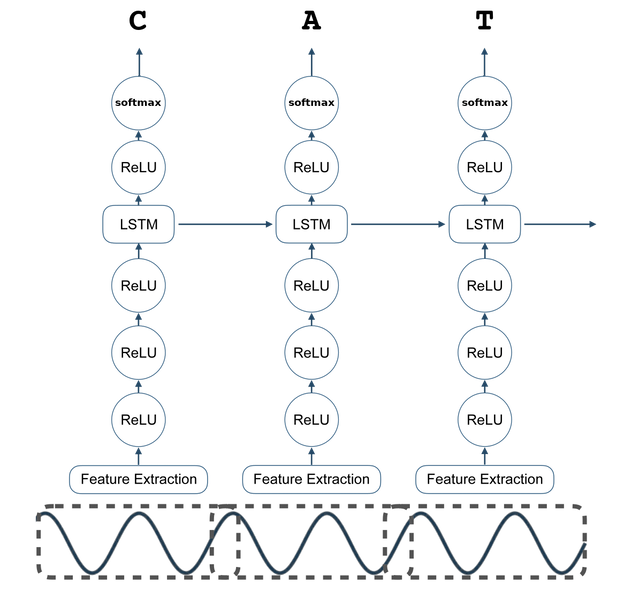
Mozilla's DeepSpeech ASR Architecture
reading is essentially a process of translation of textual sequences into their phonetic representations
spoken word thus play a fundamental role in reading acquisition
highly accurate automatic speech recognition (ASR ) systems exist for many languages but they are still strongly biased towards accurate processing of adult voices
HOWEVER: in reading acquisition or reading fostering scenarios one deals with speakers whoseutterances of sequences-to-be-read exhibit peculiar characteristics

majority of those who learn how to read are children
children are physiologically (differences in size and anatomy of vocal tract; teeth change) and cognitively different from adults
children voices are different from adult voices (e.g. Fundamental frequency F of male voice =~ 112.0 Hz; F(female voice) =~ 195.8 Hz; F(boy voice) =~ 250.0 Hz; F(girl voice) =~ 244.0 Hz
datasets for children’s speech that are publicly available are quite scarce
kidsTALC (Rumberg et al, 2022) authors report 26.2 % word-error-rate (WER) of typically developing monolingual German children
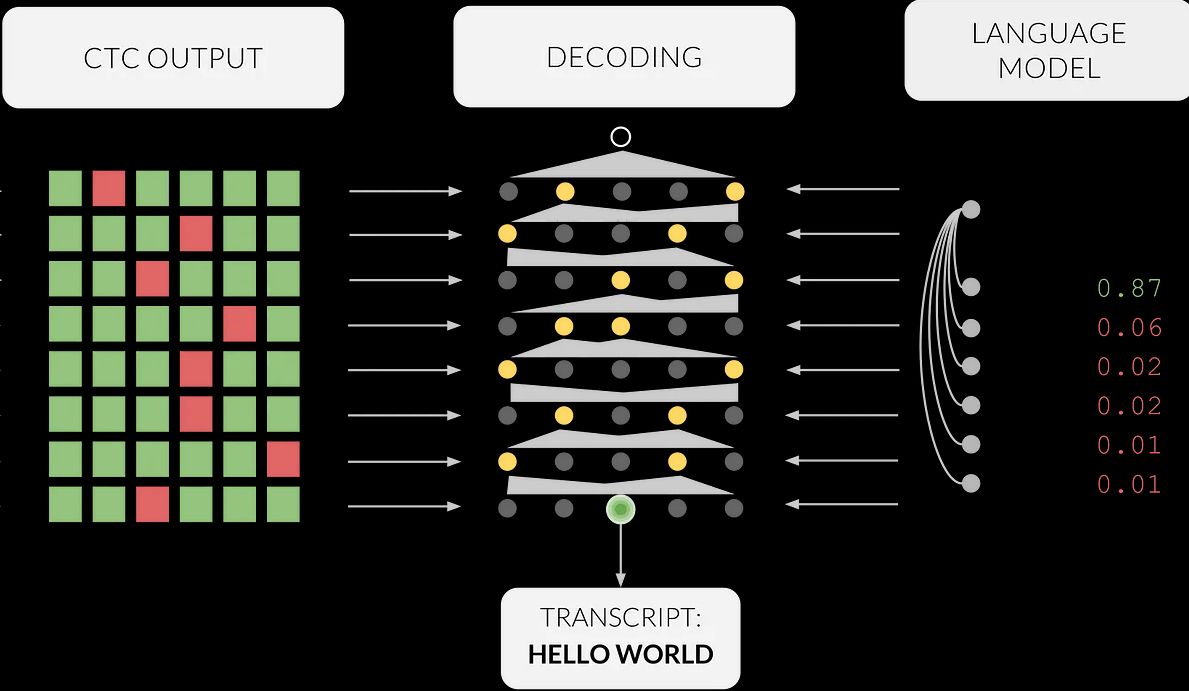
Output of Primer's ASR system combining DeepSpeech acoustic model with language model specific to German-verb recognition exercise.
in majority of reading exercises which are included in the Primer we already know the text in advance
we already know what utterances could be considered as correct lectures and which not
to every specific exercise - like vowel or syllable recognition – Primer associates a specific language model (scorer) which constraints the connectionist temporal classification (CTC) beam search to restricted amount of exercise-relevant answers
significantly constraining the search space of plausible solutions
INNOVATION 1 : implementation of exercise-specific scorers transforms a generic ASR problem (difficult) into multi-class classification problem (easier)
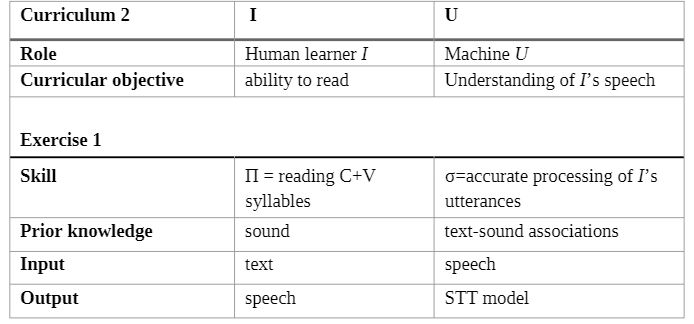
HMPL Curriculum 2 (HMPL C2) introduced in IHIET paper is a sequence of exercises at the outset of which the human individual I acquires the ability to read texts while the artificial utterance-processing tutor U acquires the ability to accurately process I's speech.
In our previous HMPL Curriculum 1 (HMPL-C1) study which focused on extending foreign language vocabulary for human learners and increase of speech-recognition accuracy of artificial learners, we have „observed increase in amount of matches between expected and predicted labels which was caused both by increase of human learner’s vocabulary, as well as by increase of recognition accuracy of machine’s speech-to-text model“ (Hromada & Kim, "Proof-of-concept of feasibility of human–machine peer learning for German noun vocabulary learning", Frontiers in Education, 2023)
.png)
Screenshot from web-based interface for mutual human-machine learning phase of HMPL-C2-E1 preliminary study.
Learner 1 (L1) - is a 5-year old – pre-school bilingual (90% German, 10% Slovak) daughter of the main author of this article
three HMPL-C2 exercise 1 (E1) sessions were executed on days 1, 3 and 5 of the study
each HMPL-C2-E1 session consisted of human-testing phase followed by a mutual human-machine learning phase
in each phase, sequences consisted of 5 repetitions of syllables started with occlusive labial consonant M or B and followed by the vowel A, E, I, O or U, thus yielding sequences from “MA MA MA MA MA” to “BU BU BU BU BU"
speech recordings collected during the learning phase subsequently provided input for the acoustic-model fine-tuning process
|
Day 1 |
Day 3 |
Day 5 |
DeepSpeech_DE |
0.96 |
0.84 |
0.64 |
KIds0 |
0.74 |
0.72 |
0.68 |
KIdsL1-1 |
0.69 |
0.78 |
0.44 |
KIdsL1-3 |
0.69 |
0.8 |
0.52 |
KIdsL1-5 |
0.69 |
0.74 |
0.48 |
sequences of five vowels resp. CV syllables which were displayed by DP were considered to provide the “reference”; output of the model yielded the hypotheses
data provided by L1 during three testing phases on days 1, 3 and 5 were evaluated by means of 5 different models
DeepSpeech_de = baseline model; KIds-0 : Deepspeech_de fine-tuned with kidsTALC; KIds-L1-1 : KIds-0 fine-tuned with data provided by L1 during day 1 learning phase;KIds-L1-3 : KIds-1 fine-tuned with data provided by L1 during day 3 learning phase;KIds-L1-5 : KIds-5 fine-tuned with data provided by L1 during day 5 learning phase
NOTE: WER-decrease between rows corresponds to increase of accuracy of the ASR model; WER-decrease between columns points to increase in L1's reading competence
As of 2023, there exists no publicly available ASR model which could accurately and reliably process child speech.
In our IHIET 2023 article, we introduce two innovations with which the problem can be partially bypasssed in context of digitally supported reading acquisition app:
In concrete terms, we have shown that after three sessions focusing on acquisition of grapheme-vowel and CV-bigrapheme correspondences had lead, in case of one particular learner, to decrease of WER from 96% to 48%.